Update
- 2025.03.01: Codes and checkpoints are released at GitHub!
- 2025.02.27: AVIS got accepted to CVPR 2025!
- 2024.11.12: Our project page is now available!
- 2024.11.11: The AVISeg dataset has been uploaded to OneDrive, welcome to download and use!
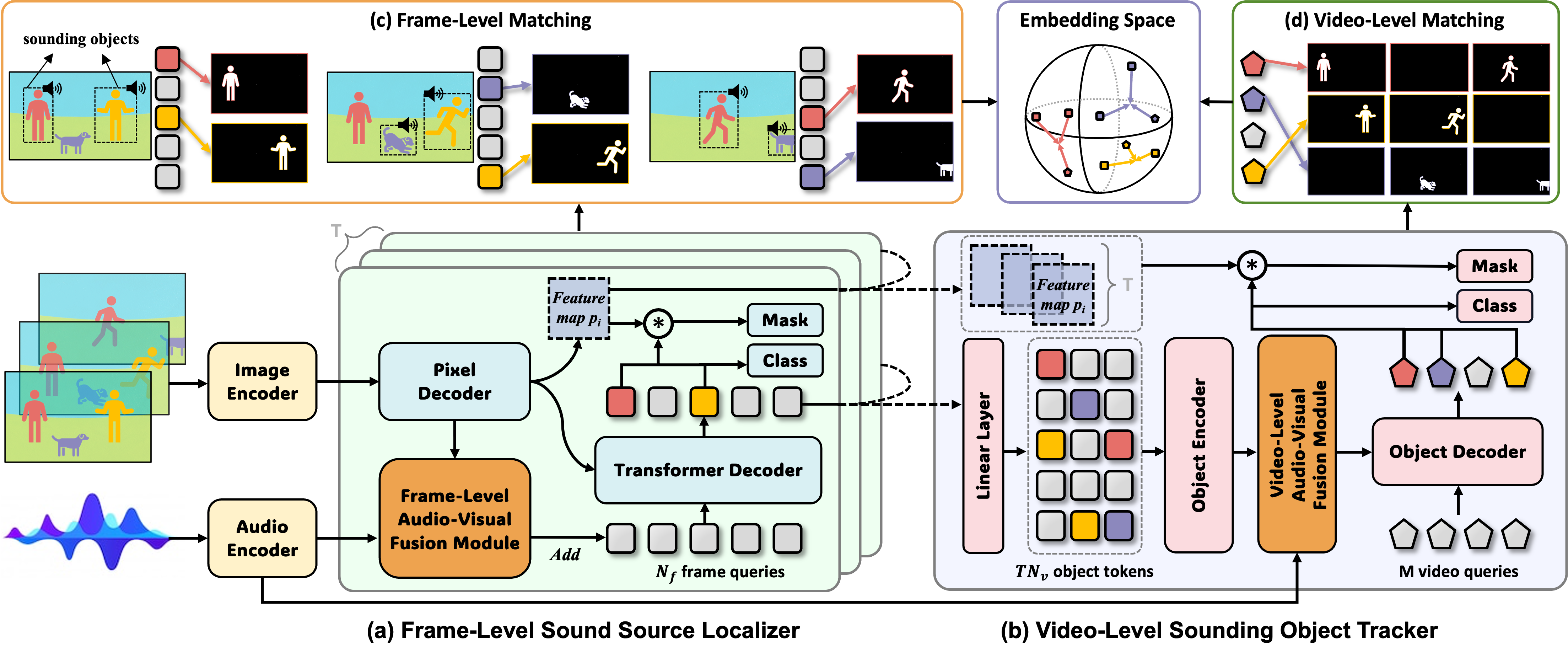
What is AVIS task?
Vision and hearing are our primary channels of communication and sensation. Audio-visual collaboration is beneficial for humans to better perceive and interpret the world. Humans have the ability to associate mixed sounds with object instances in complicated realistic scenarios. Imagine a cocktail-party scenario: when a group of people is speaking, we can not only locate the sound sources but also determine how many people are talking. Inspired by this human perception, we explore instance-level sound source localization in long videos and propose a new task, namely audio-visual instance segmentation (AVIS), which It requests a model to simultaneously classify, segment and track sounding object instances—identify which objects are making sounds, infer where the sounding objects are, and monitor when they are making sounds. This new task facilitates a wide range of practical applications, including embodied robotics, virtual reality, video surveillance, video editing, etc. Moreover, it can serve as a fundamental task for evaluating the comprehension capabilities of multi-modal large models.
Comparison of different audio-visual segmentation tasks. (a) Audio-Visual Object Segmentation (AVOS) only requires binary segmentation. (b) Audio-Visual Semantic Segmentation (AVSS) associates one category with every pixel. (c) Audio-Visual Instance Segmentation (AVIS) treats each sounding object of the same class as an individual instance.
Audio-visual instance segmentation is related to several existing tasks. For example, audio-visual object segmentation (AVOS) is to separate sounding objects from the background region of a given audible video, as shown in Figure \ref{fig_intro} (a). Unlike AVOS being tasked with binary foreground segmentation, audio-visual semantic segmentation (AVSS) aims at predicting semantic maps that assign each pixel with a specific category. To accomplish the above tasks, many works extend the image segmentation frameworks to the video domain, and design various audio-visual fusion modules for sound source localization. Despite promising performance in the AVSBench dataset, current methods still suffer from two limitations in real-world scenarios. First, these methods fail to differentiate two sounding objects with the same category, such as the woman, man, left ukulele and right ukulele depicted. Second, these methods focus on 5- or 10-second trimmed short videos and ignore long-range modeling abilities, which may lead to weak performance in real world.
What is AVISeg dataset?
One potential reason that the AVIS task is rarely studied is the absence of a high-quality dataset. Despite the existence of audio-visual segmentation datasets, none are directly applicable to our proposed task, due to lacking instance-level annotations and long-form videos. To explore audio-visual instance segmentation and evaluate the proposed methods, we create a new large-scale benchmark called AVISeg.
Basic informations
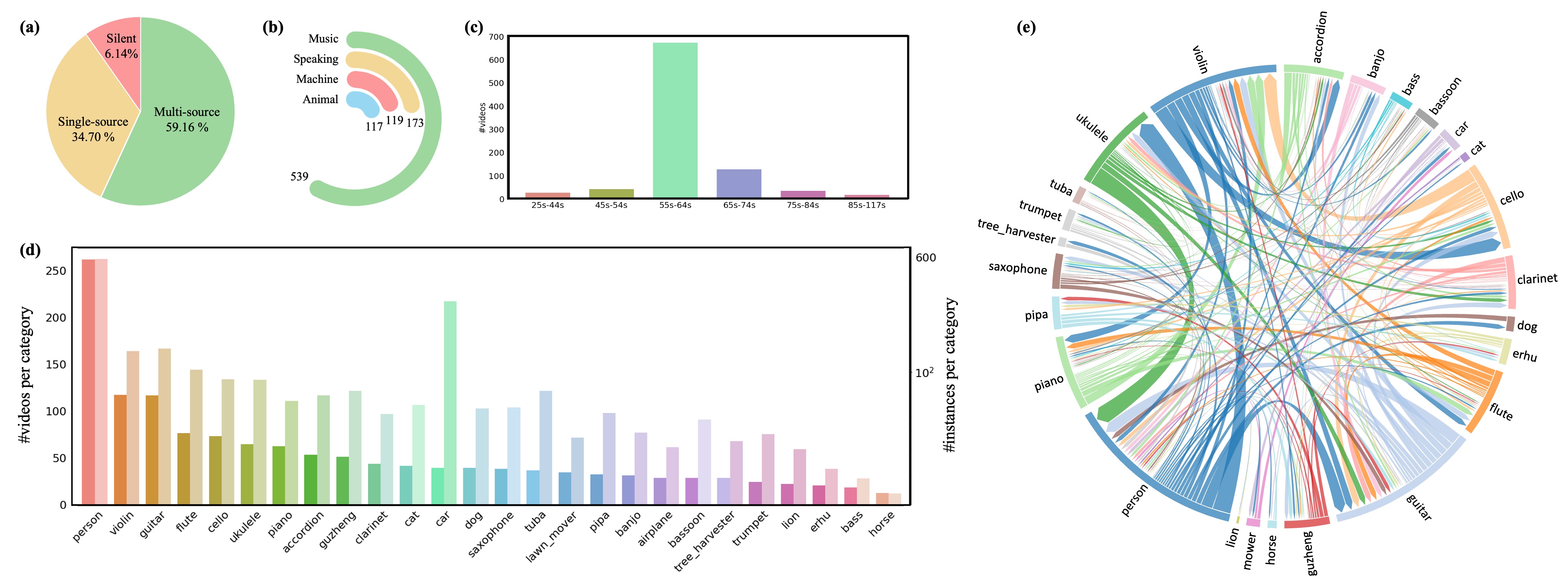
Our released AVISeg dataset satisfies the following criteria: 1) It focuses on long-term videos, bringing them much closer to real applications. 2) It contains 26 common sound categories, spanning 4 dynamic scenarios: Music, Speaking, Machine and Animal. 3) It involves some challenging cases, such as videos with silent sound sources, single sound source, and multiple sources.
Characteristics
- 4 typical scenes
- 26 categories
- 926 long videos
- 61.4 seconds for each video
- Diversity, complexity and dynamic
Personal data/Human subjects
Videos in AVISeg are public on YouTube, and annotated via crowdsourcing. Our dataset does not contain personally identifiable information or offensive content.

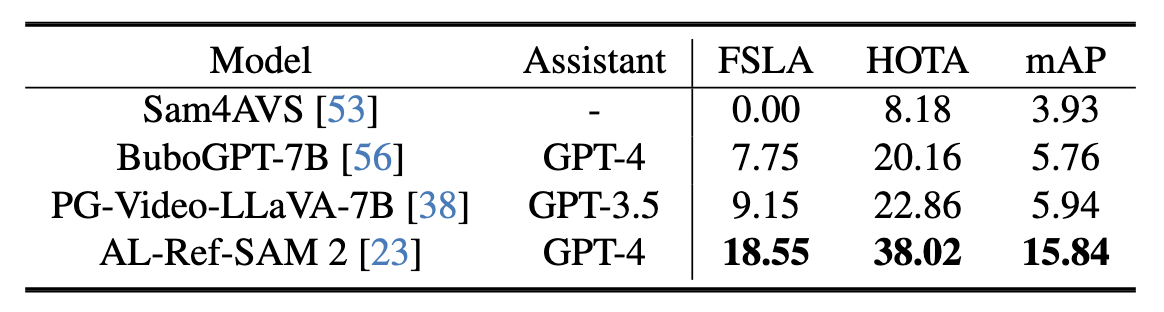 Zero-shot results of different multi-modal large models for audio-referred visual grounding on the AVISeg test set.
Zero-shot results of different multi-modal large models for audio-referred visual grounding on the AVISeg test set.